RIHA: Report-Image Hierarchical Alignment for Radiology Report Generation
Abstract
Radiology report generation remains challenging because it requires precise alignment between complex visual patterns and long-form clinical narratives. Existing methods often treat reports as flat sequences, overlooking their inherent hierarchical structure and limiting fine-grained visual-text correspondence. RIHA addresses this challenge through hierarchical cross-modal alignment at paragraph, sentence, and word levels. It introduces a Visual Feature Pyramid (VFP) and a Text Feature Pyramid (TFP) to represent multi-scale visual information and multi-granularity textual semantics, and aligns them through a Cross-modal Hierarchical Alignment (CHA) module based on optimal transport. In addition, Relative Positional Encoding (RPE) is incorporated into the decoder to improve token-level alignment and contextual consistency. This design enables RIHA to better capture the structured nature of clinical reasoning and generate more accurate and coherent radiology reports.
Key Contributions
- We propose RIHA, a hierarchical cross-modal alignment framework for radiology report generation, aligning visual and textual features at paragraph, sentence, and word levels.
- We design a Visual Feature Pyramid (VFP) and a Text Feature Pyramid (TFP) to extract multi-scale visual features and multi-granularity textual representations.
- We introduce a Cross-modal Hierarchical Alignment (CHA) module based on optimal transport, enabling distribution-level alignment across modalities and semantic levels.
- We incorporate Relative Positional Encoding (RPE) into the decoder to improve token-level alignment and enhance semantic consistency in generated reports.
Motivation
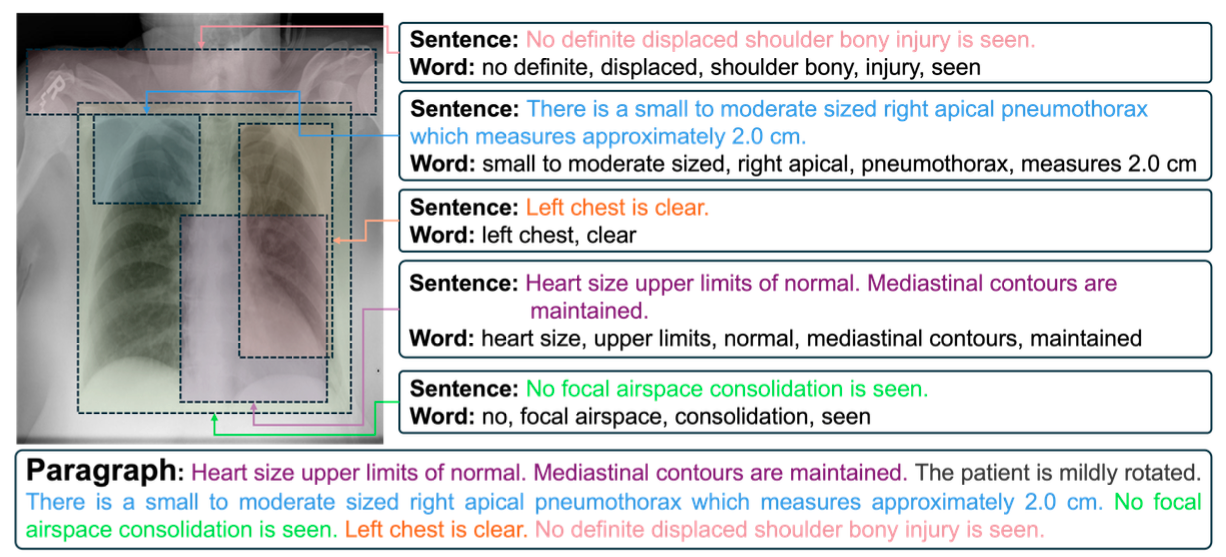
Radiology reports are inherently hierarchical: paragraph-level impressions provide overall clinical context, sentence-level descriptions detail specific anatomical findings, and word-level terminology captures precise medical measurements. Existing RRG methods typically treat reports as flat token sequences, missing the opportunity to leverage this structured hierarchy. RIHA is motivated by the need to establish synchronized cross-modal correspondences at multiple semantic levels simultaneously, mirroring the hierarchical reasoning process of clinical radiologists.
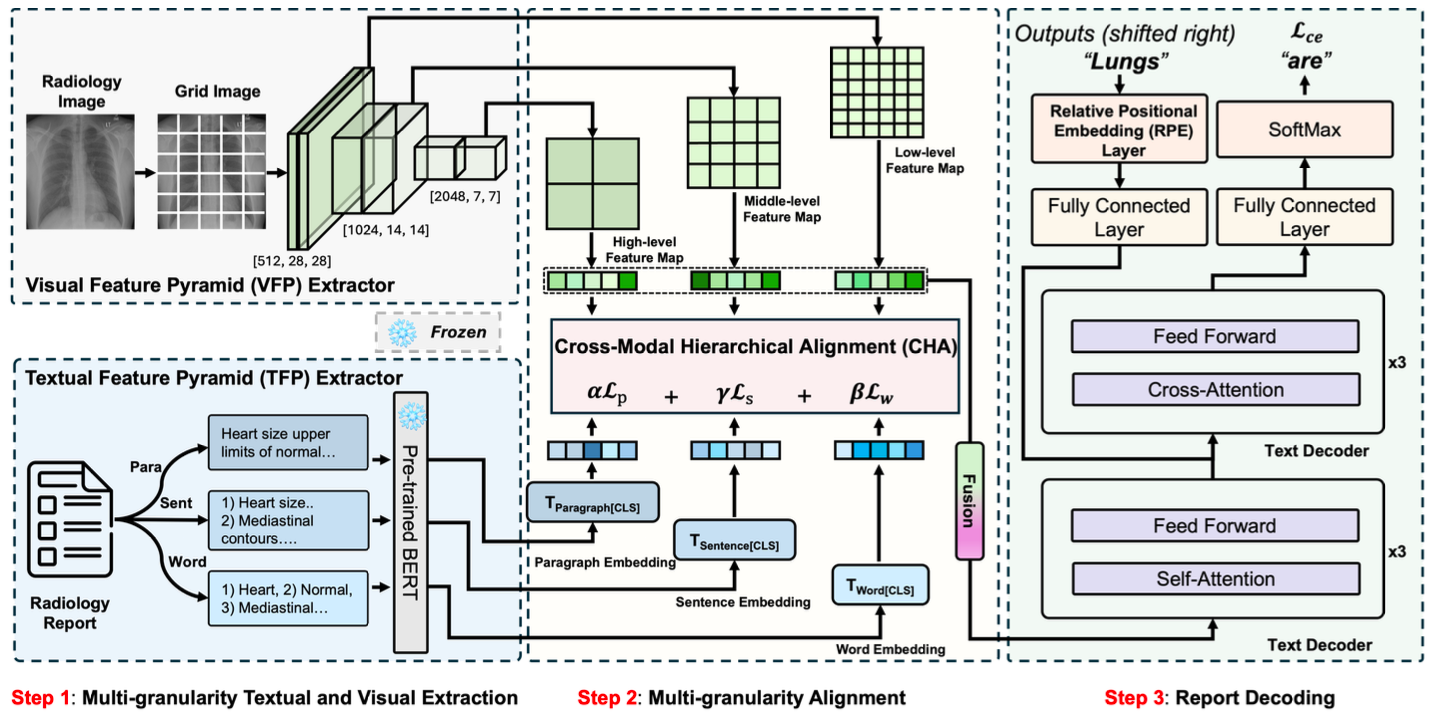
Method Overview
RIHA is built around the idea that radiology reports are inherently hierarchical, with paragraph-level summaries, sentence-level findings, and word-level clinical terms reflecting different stages of diagnostic reasoning. To model this structure, RIHA first extracts multi-scale visual features with a Visual Feature Pyramid (VFP) and multi-granularity textual features with a Text Feature Pyramid (TFP). These representations are then aligned through the Cross-modal Hierarchical Alignment (CHA) module, which formulates visual-text matching as an optimal transport problem across different semantic levels. Finally, the aligned visual features are decoded into reports with the help of Relative Positional Encoding (RPE), which improves token-level contextual modeling and strengthens the coherence of generated sentences. This design allows RIHA to bridge the gap between structured clinical language and heterogeneous visual evidence more effectively than conventional flat-sequence approaches.
Results
We evaluate RIHA on two benchmark datasets, IU-Xray and MIMIC-CXR, using both natural language generation (BLEU, METEOR, ROUGE-L, CIDEr) and clinical efficacy metrics.
The results show that RIHA consistently outperforms existing state-of-the-art methods across both datasets. The improvements are attributed to the proposed hierarchical alignment mechanism, which enables more precise mapping between visual features and structured report components.
Figure 3 presents qualitative comparisons of generated reports on the MIMIC-CXR dataset. Compared with the baseline model, RIHA generates reports that more faithfully reflect the ground-truth clinical findings, as indicated by the higher overlap of highlighted terms. In particular, RIHA reduces both omission errors, where important findings are missed, and hallucination errors, where unsupported observations are introduced. This improvement is closely related to the proposed hierarchical alignment mechanism, which enables the model to associate visual evidence with textual content at paragraph, sentence, and word levels, leading to more structured and clinically consistent reports.
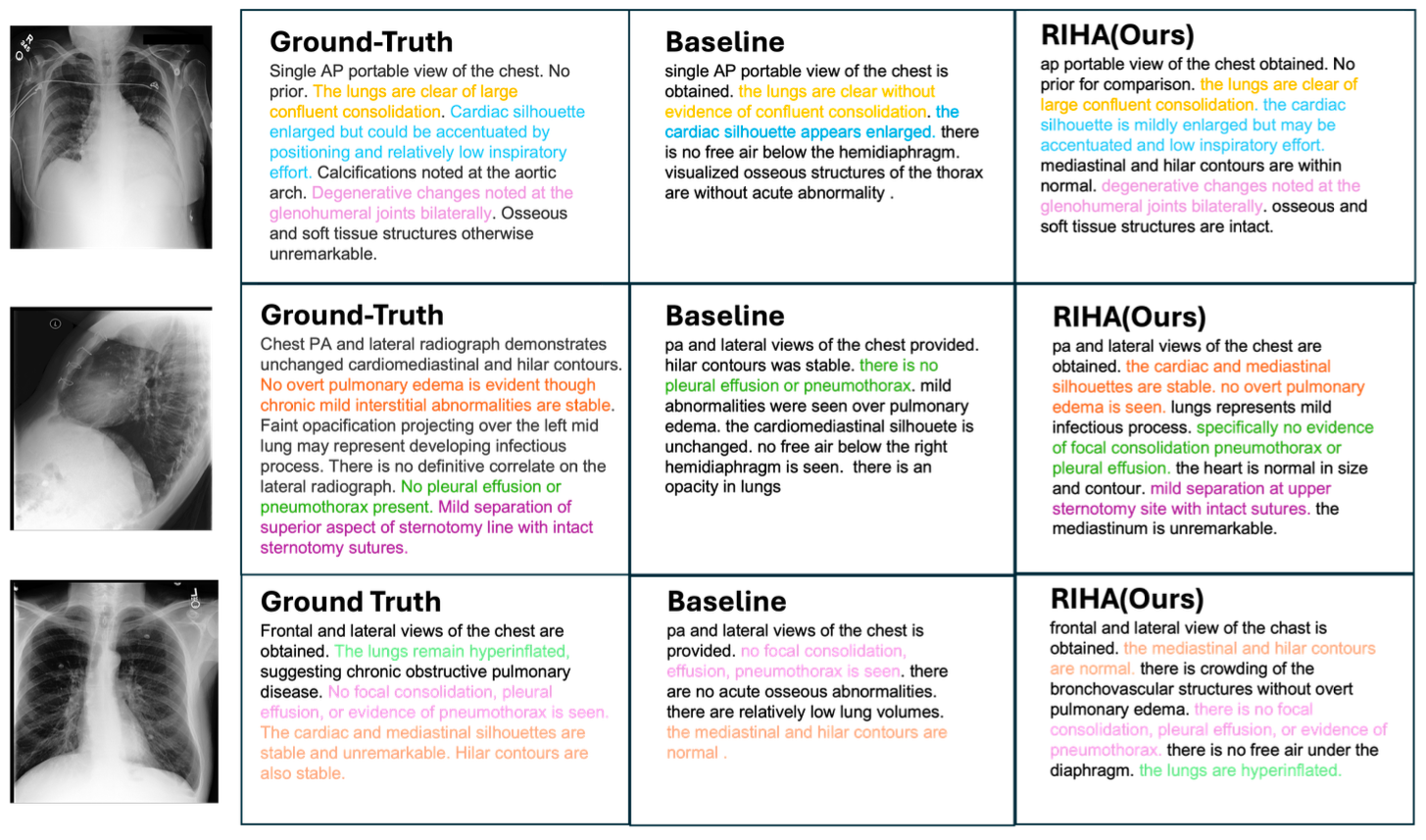
Figure 4 provides further insight into how this improvement is achieved. The attention map visualizations show that RIHA attends more precisely to clinically relevant regions corresponding to each keyword, whereas the baseline model often exhibits diffuse or misaligned attention. This suggests that the proposed alignment strategy improves the model's ability to ground textual tokens in specific visual evidence. Such fine-grained visual-text correspondence is particularly important in clinical report generation, where interpretability and reliability depend on whether textual descriptions are supported by the appropriate image regions.
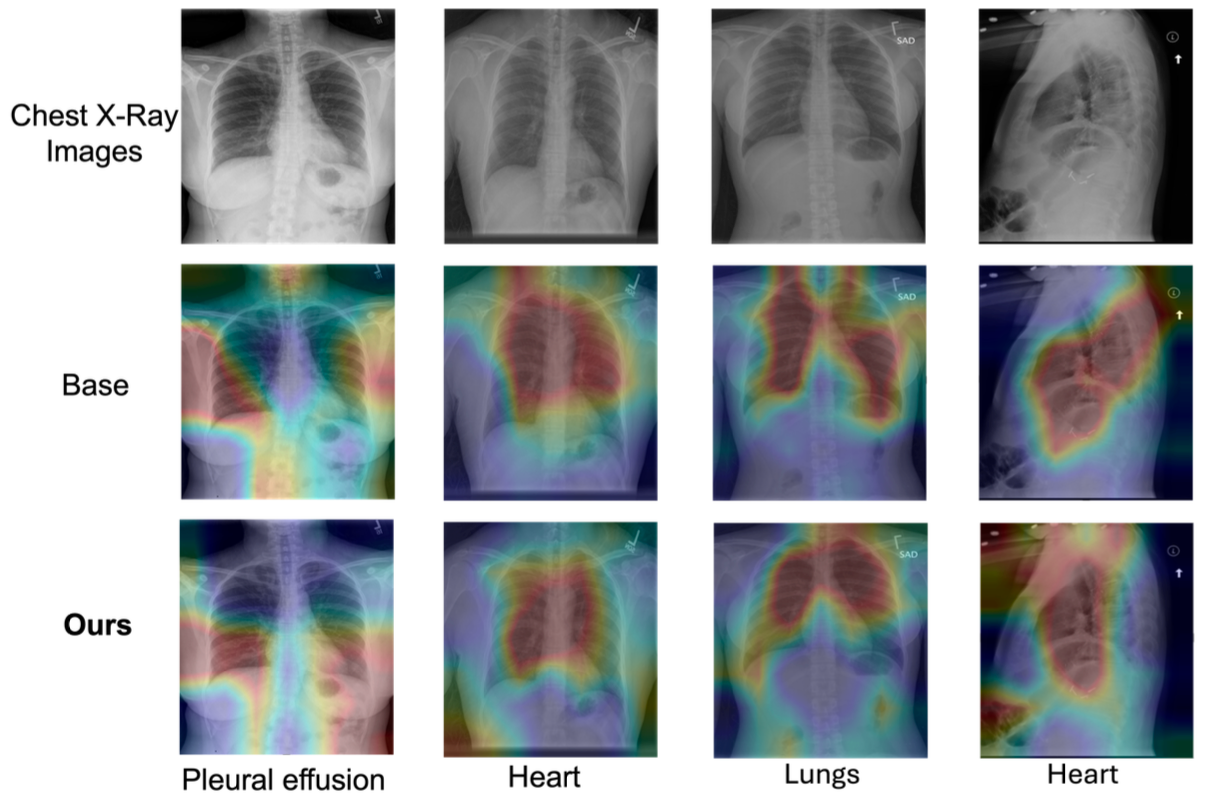
Together, these results demonstrate that RIHA not only improves linguistic quality, but also strengthens clinically meaningful alignment between images and reports, which is essential for trustworthy radiology report generation.
Citation
@article{chen2026riha,
title={RIHA: Report-Image Hierarchical Alignment for Radiology Report Generation},
author={Chen, Yucheng and Yu, Yang and Shi, Yufei and Xiong, Conghao and Yang, Xulei and Yeo, Si Yong},
journal={IEEE Journal of Biomedical and Health Informatics},
year={2026},
doi={10.1109/JBHI.2026.3670023}
}