MedUnifier: Unifying Vision-and-Language Pre-training on Medical Data with Vision Generation Task using Discrete Visual Representations
Abstract
Current Vision-Language Pre-training (VLP) approaches in the medical domain primarily focus on feature extraction and cross-modal comprehension, with limited attention to generating or transforming visual content. This gap restricts the development of comprehensive multi-modal models that can both understand and create medical visual content.
We propose MedUnifier, a novel framework that seamlessly integrates text-grounded image generation capabilities with multi-modal learning strategies for medical data. Our approach employs visual vector quantization for cross-modal learning, enabling more comprehensive multi-modal alignment through discrete visual representations.
MedUnifier demonstrates superior performance across uni-modal, cross-modal, and multi-modal tasks, showing its ability to generate realistic medical images and reports while maintaining strong understanding capabilities across diverse medical imaging modalities.
Key Contributions
- Novel Med-VLP Framework: First to unify vision-language pre-training with language-guided visual generation in the medical domain
- Text-Grounded Image Generation (TIG): Innovative module designed to capture detailed medical image information through discrete visual representations
- Comprehensive Evaluation: Demonstrated superior performance across uni-modal, cross-modal, and multi-modal medical tasks
- Discrete Visual Representations: Novel use of vector quantization to enable more effective cross-modal alignment in medical imaging
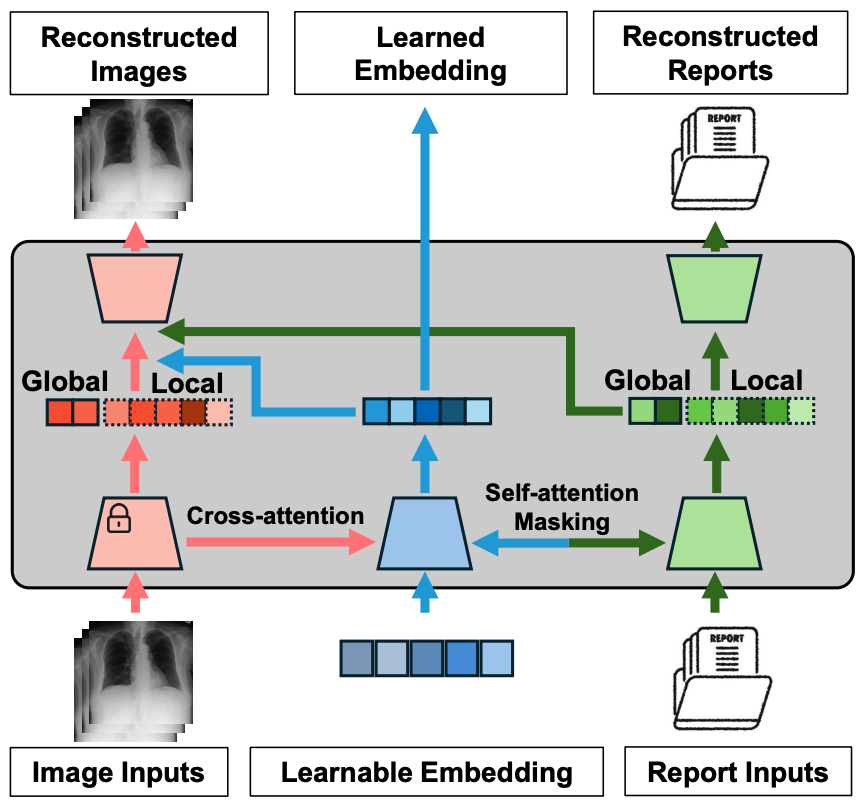
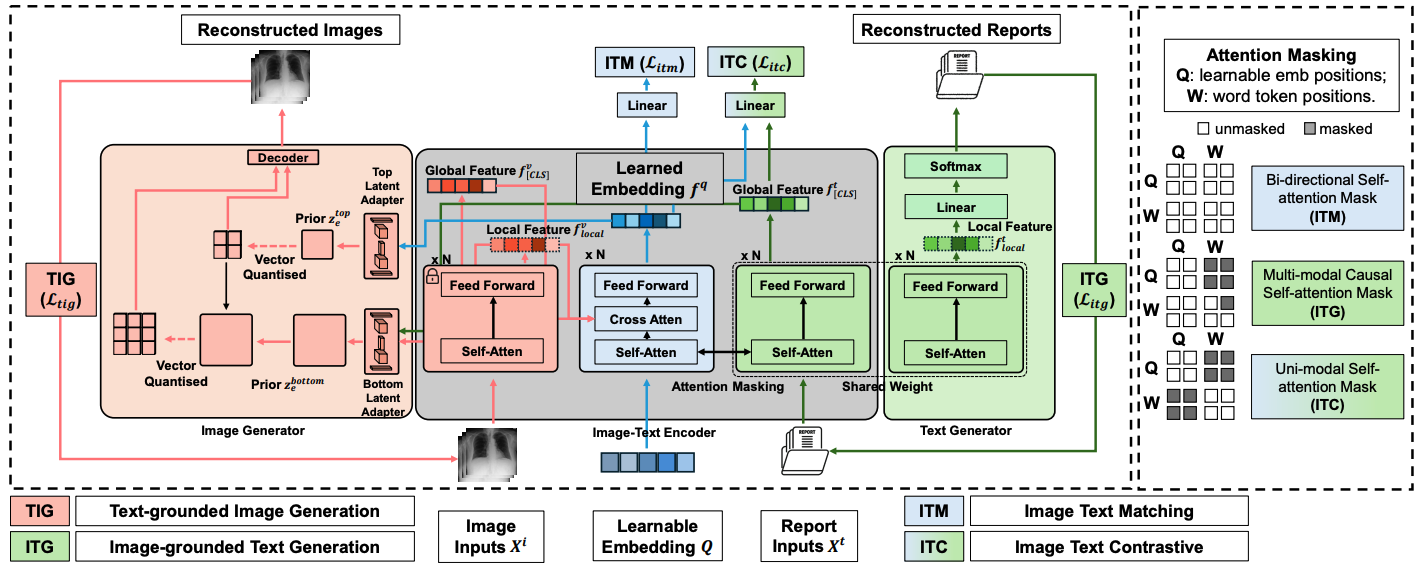
Method Overview
MedUnifier employs a transformer-based architecture with learnable embeddings and incorporates four key learning objectives:
- Image-Text Contrastive Learning (ITC): Aligns visual and textual representations in a shared embedding space
- Image-Text Matching (ITM): Enables fine-grained understanding of image-text correspondence
- Image-Text Generation (ITG): Generates descriptive medical reports from visual input
- Text-Grounded Image Generation (TIG): Novel capability to generate medical images from textual descriptions
The framework utilizes vector quantization to learn discrete visual representations, which facilitates more effective cross-modal alignment and enables the generation of high-quality medical images guided by textual descriptions.
Results & Performance
MedUnifier demonstrates state-of-the-art performance across multiple medical imaging tasks:
- Uni-modal Tasks: Superior performance on medical image classification and report generation
- Cross-modal Tasks: Enhanced image-text retrieval and matching capabilities
- Multi-modal Tasks: Comprehensive understanding and generation across multiple medical imaging modalities
- Generation Quality: High-fidelity medical image synthesis guided by textual descriptions
The model's ability to both understand and generate medical content positions it as a significant advancement toward an "all-in-one" VLP model for medical applications.

Impact & Applications
MedUnifier represents a significant step toward developing comprehensive AI systems for medical imaging that can both analyze and generate medical content. The framework's versatility makes it applicable to various clinical scenarios including:
- Medical Report Generation: Automatic generation of detailed diagnostic reports from medical images
- Educational Content Creation: Synthesis of medical images for training and educational purposes
- Cross-modal Medical Understanding: Enhanced interpretation of complex medical data across different modalities
- Clinical Decision Support: Comprehensive analysis combining visual and textual medical information
Citation
@inproceedings{zhang2025medunifier,
title={MedUnifier: Unifying Vision-and-Language Pre-training on Medical Data with Vision Generation Task using Discrete Visual Representations},
author={Zhang, Ziyang and Yu, Yang and Chen, Yucheng and Yang, Xulei and Yeo, Si Yong},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages={29744--29755},
year={2025}
}
Published in CVPR 2025
IEEE/CVF Conference on Computer Vision and Pattern Recognition